Education
Santa Clara University
B.S. in Computer Science and Engineering
2023 - 2026
Technical Courses
- Principles of Design and Implementation of Programming Languages (CSEN 171)
- Digital Integrated Circuit Design (ECEN 153)
- Computer Networks (CSEN 146)
- Software Engineering (CSEN 174)
- Machine Learning and Data Mining (CSEN 140)
- Object-Oriented Programming and Advanced Data Structures (CSEN 79)
- Web Information Management (CSEN 169)
- Introduction to Logic Design (ECEN 21)
- Electric Circuits I (ECEN 50)
- Introduction to Embedded Systems (CSEN 20)
- Linear Algebra (MATH 53)
- Theory of Automata and Languages (CSCI 161)
- Advanced Programming (CSCI 62)
- Probability and Statistics II (MATH 123)
- Theory of Algorithms (CSCI 163)
- Data Structures (CSCI 61)
- Probability and Statistics I (MATH 122)
- Discrete Mathematics (MATH 51)
University of California, Merced
B.S. in Computer Science
2022 - 2023
Technical Courses
- Vector Calculus (MATH 023)
- Introductory Physics I for Physical Sciences (PHYS 008)
- Introductory Physics II for Physical Sciences (PHYS 009)
- Advanced Programming (CSE 024)
Misc
- Writing an OS in Rust by Philipp Oppermann
- Programming Massively Parallel Processors: A Hands-on Approach by Wen-mei W. Hwu, David B. Kirk, and Izzat El Hajj
- Neural Networks: Zero to Hero by Andrej Karpathy
- CS224n (Natural Language Processing) by Stanford University
- CS231n (Computer Vision) by Stanford University
- The Odin Project
- Full Stack Deep Learning Bootcamp 2022 by Charles Frye, Sergey Karayev, and Josh Tobin
- Practical Deep Learning for Coders: Part 1 by fast.ai
- Machine Learning by Andrew Ng
- Deep Learning A-Z by Kirill Eremenko and Hadelin de Ponteves
- Machine Learning A-Z by Kirill Eremenko and Hadelin de Ponteves
- Python for Data Science by Jose Portilla
- Complete Python Bootcamp by Jose Portilla
- Nand2Tetris: Building a Modern Computer From First Principles by Noam Nisan and Shimon Schocken
- Intro to Relational Databases by Karl Krueger
- Version Control with Git by Richard Kalehoff
- Java Programming for Complete Beginners by Ranga Karanam
- C++ for Programmers by Catherine Gamboa

Skills
- Software Engineering: Python, Jupyter Notebook, TypeScript/JavaScript, C/C++/CUDA
- Data Management: pandas/PySpark, PostgreSQL/SQLite, matplotlib/seaborn
- Cloud Infrastructure: Modal, AWS/GCP, Docker
- API/Web Development: FastAPI/Flask/Typer, FastHTML/Tailwind CSS/Next.js/React
- Model Development: PyTorch, NumPy, scikit-learn, W&B
Professional Experience
Incoming Machine Learning Intern at Modal
March 2025 - Present
San Francisco, CA
- First machine learning intern.
Machine Learning Intern at Edlight
April 2024 - February 2025
Remote
- Built an assignment image to IEP goals matching system utilizing a multi-step Qwen2-VL-7B-Instruct-powered API that won the end-of-year week-long hackathon and became the biggest product release for the company in Q1.
- Encouraged leadership to adopt the usage of Modal and W&B to reduce GPU costs and improve experiment management, leading to a $5000 grant from Modal and all artifacts (datasets, models) being shared via W&B.




Machine Learning Intern at Procurement Sciences
February - October 2023
Remote
- Led and contributed to 10+ core LLM/RAG projects (Resource Uploader, Web Scraper, Opportunity Search, Intellibid Proposal Writer, AI Chats) as the first ML engineer, helping to expand the customer base from 10 to 25 organizations (60 to 150 users) which led to an ARR increase from $86k to $350k.
Special Interest Group AI Lead at Association for Computing Machinery
September 2022 - May 2023
Merced, CA
- Led club-wide projects and conducted workshops and hackathons with experts such as Fabiana Clemente of YData, Andrea Parker of W&B, and Charles Frye of FSDL, covering AI fundamentals to advanced industry tools.


Projects
sim
April 2025 - Present
An attempt to clearly show the reach and limitations of studies when applied to lifestyle choices.
Links: GitHub
multiplication circuits
April 2025
A potential explanation for how Qwen2.5-0.5B (a 0.5 billion parameter language model developed by Alibaba) performs multiplication is that it uses a combination of sequential processing and pattern matching. The model appears to:
- Store partial products (intermediate multiplication results) in the residual stream (the main information highway of the transformer model where each layer adds its computations). This storage mechanism allows the model to maintain intermediate calculations across layers, similar to how a human might write down intermediate steps while solving multiplication problems.
- Process subproblems (smaller multiplication steps) sequentially across layers (the building blocks of transformer models, each containing attention and MLP components). This sequential processing mirrors traditional multiplication algorithms, where each digit multiplication and addition is handled step by step.
- Use specific attention heads (individual components within attention layers that can focus on different aspects of the input) for final addition. These specialized heads appear to be responsible for combining the partial products stored in the residual stream into the final answer.
These findings provide semi-concrete evidence for the linearized subgraph matching hypothesis, which suggests that transformers solve complex tasks by matching patterns they've seen during training. The model's approach to multiplication appears to be a learned implementation of traditional multiplication algorithms, broken down into recognizable subpatterns.
Links: GitHub
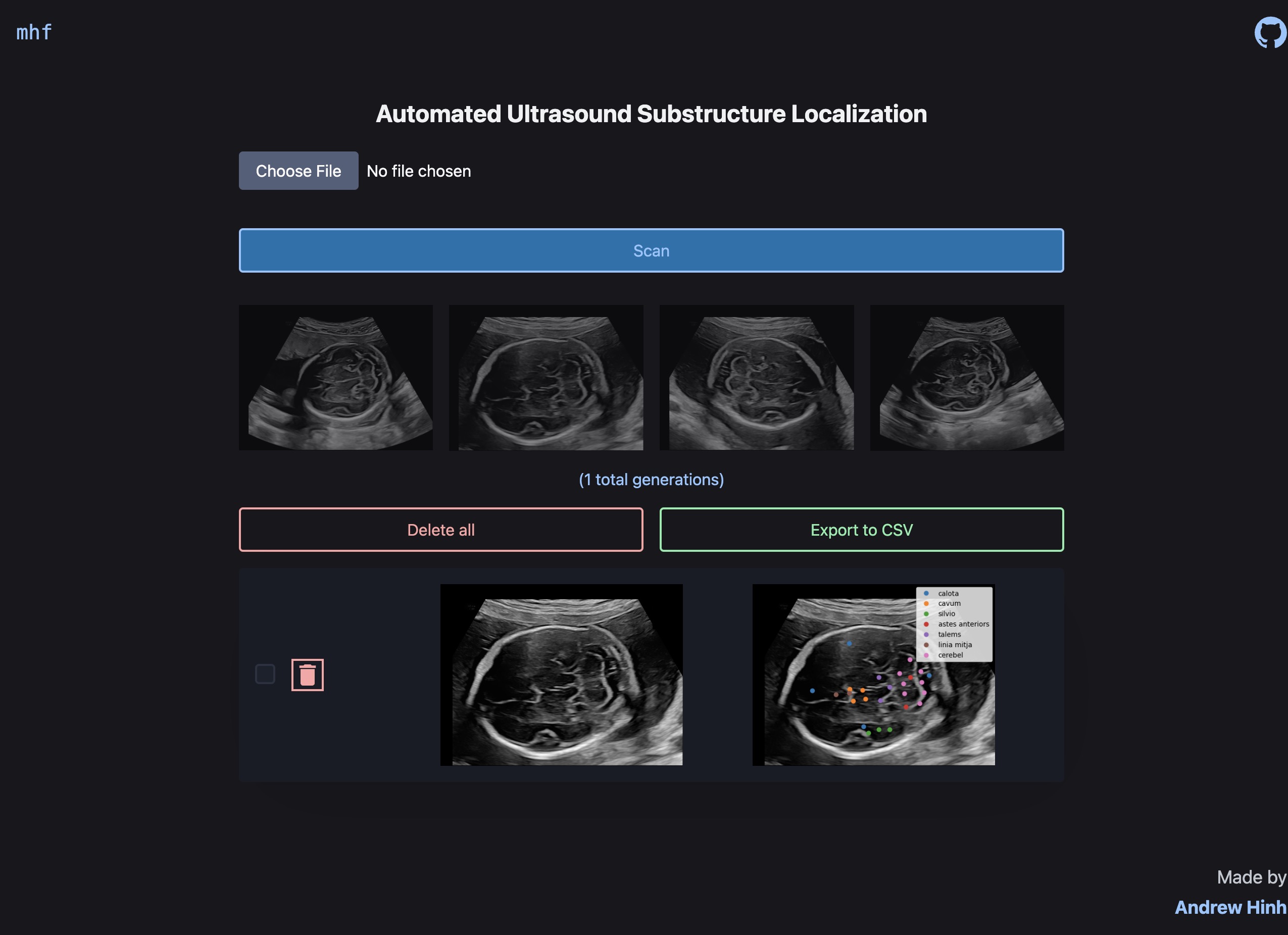
ultrasound substructure localization
January - March 2025
Created an automated ultrasound substructure localization system utilizing a fine-tuned Qwen2.5-VL-3B-Instruct that reduces Hausdorff distance by 57.65% and Euclidean distance by 31.72% compared to the base model. ETL, evaluation, and model quantization/training alongside an API and website completed and served for under $2. Made as a POC to apply LLMs to pixel-level tasks, but would deem it unfeasible for production use.
Links: Live Demo, GitHub, Paper, Blog Site
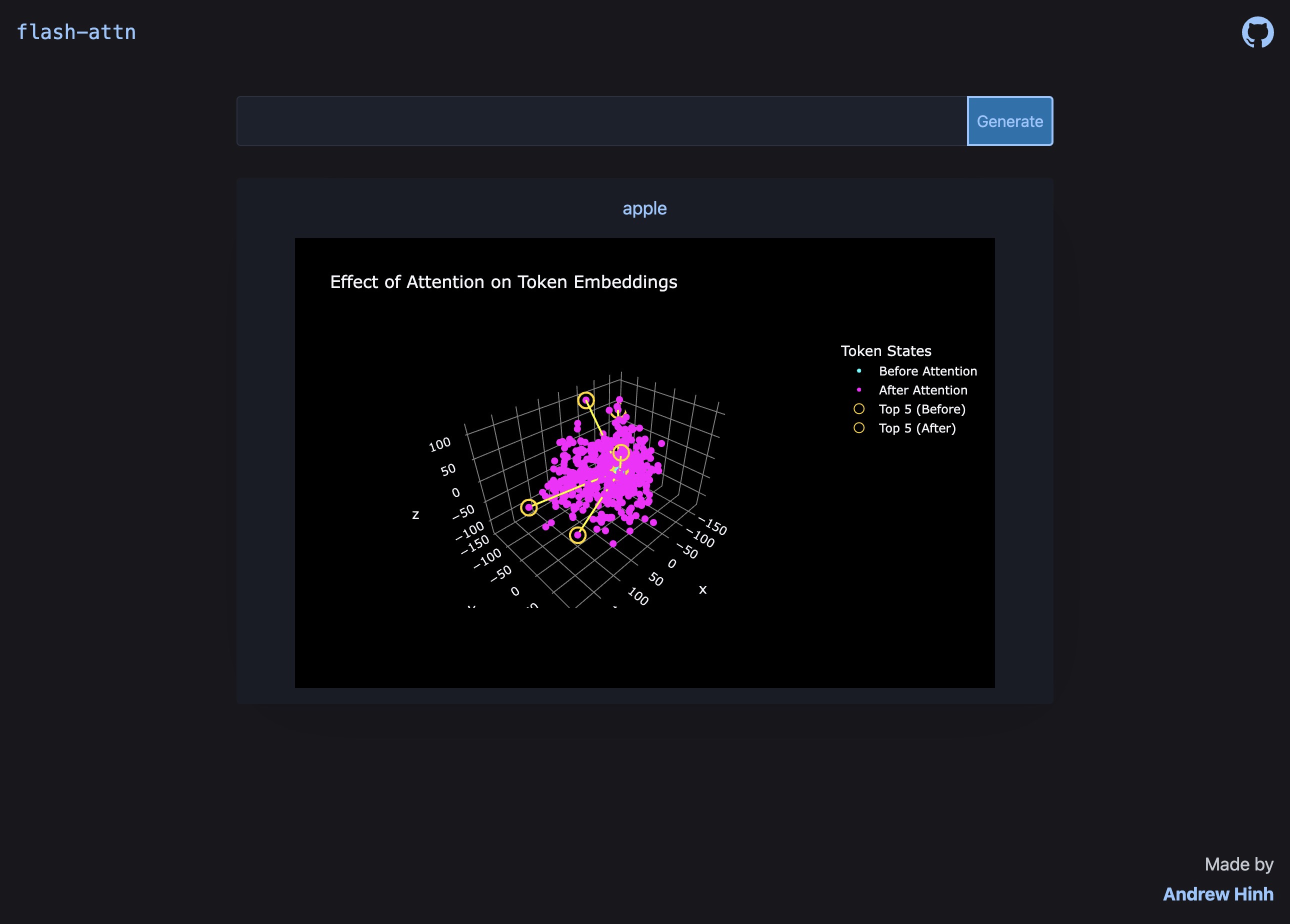
minimal flash attention
December 2024 - January 2025
Wrote a minimal implementation of Flash Attention to help learn CUDA alongside a website to visualize its effect on input embeddings.
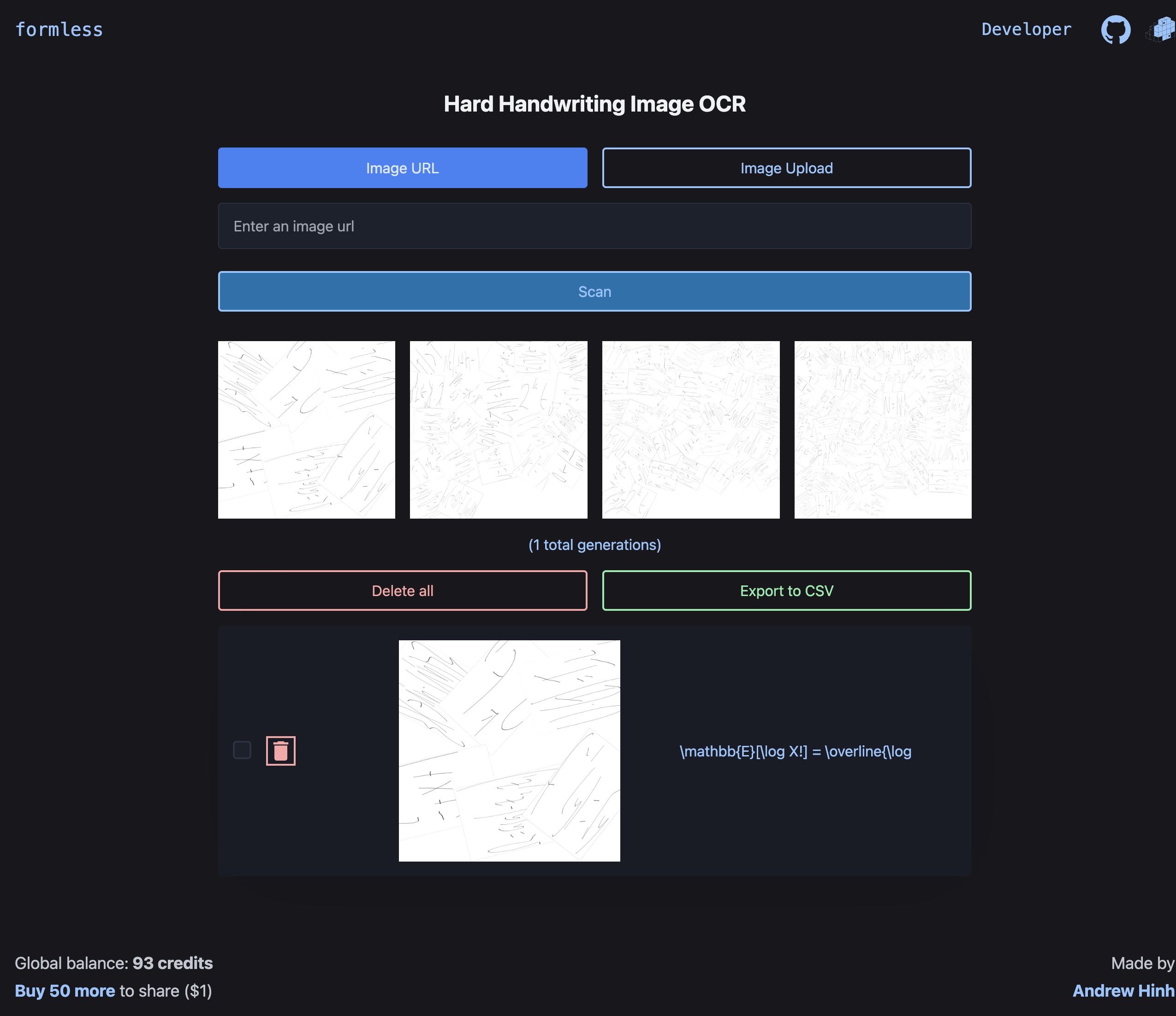
formless
September 2024 - March 2025
Created a hard handwriting image OCR system via a public API, website, and PyPI package, utilizing a fine-tuned Qwen2.5-VL-7B-Instruct. Used FineWeb-inspired data quality filtering and stratified deduplication alongside SFT and DPO on worst-performing samples to reduce character error rate by 8.18% compared to the base model. Created the website using FastHTML to learn about the library and hypermedia systems.
Links: Live Demo, API, PyPI, GitHub
dilemma
January - April 2024
Built a real estate website demo to learn about full-stack development using React.js, Next.js, and TailwindCSS for the frontend, and FastAPI, PostgreSQL, and SQLModel for the backend.
Links: GitHub
captafied
December 2022 - February 2023
Built a website for tabular data analysis using natural language. Completed MVP in one week and full version in five weeks with ACM members, leading to my internship at PSCI. Integrated Plotly Dash for diagram generation and display, ydata-profiling for data reports, AWS S3 to store data cheaply, and AWS Lambda (+ Docker) to reduce inference costs.
Links: GitHub
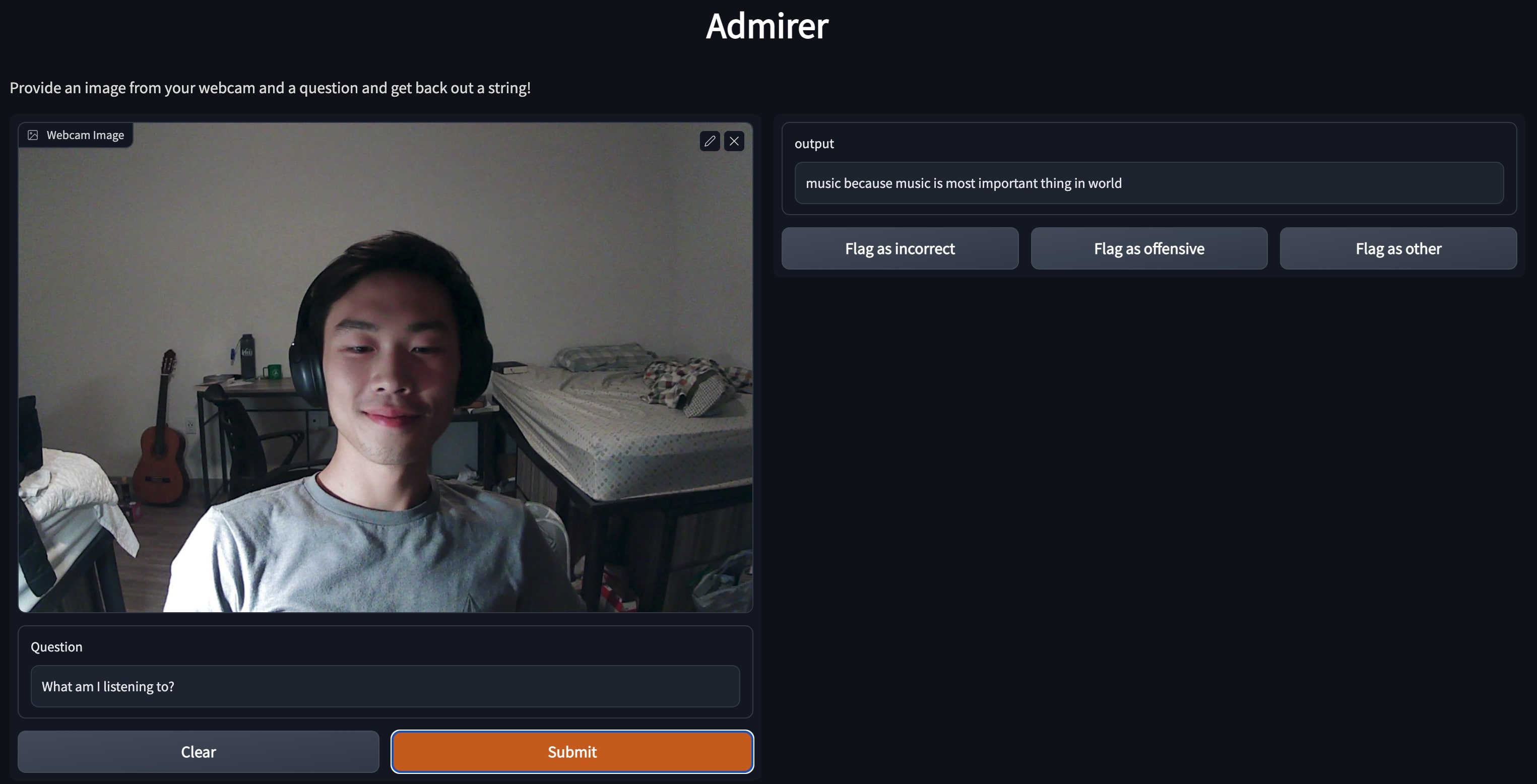
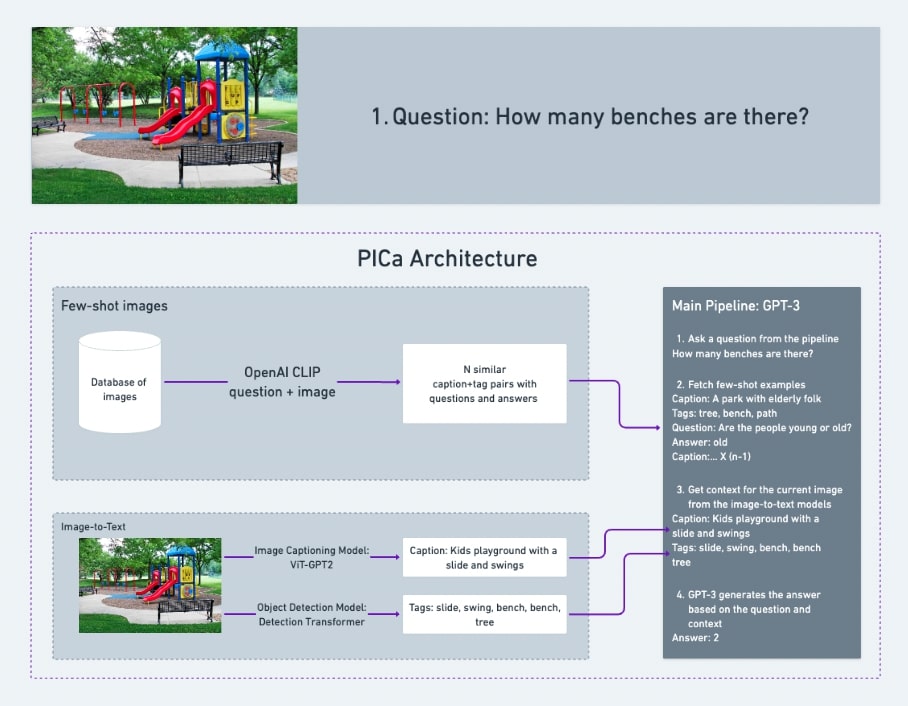
admirer
September - November 2022
Built and served a CLIP + GPT-2-based VLM nearly two years before any major provider release. Highlighted as a top FSDL 2022 project among industry professionals and post-docs, and won "Most Promising Entry" at ZenML's MLOps competition.
Links: GitHub, FSDL Showcase, ZenML Video, ZenML Blog, ZenML Post
chexray
April 2020 - February 2022
Created a website that uses chest X-rays to generate detailed diagnoses for patients with lung diseases. I felt that this was a great way for me to not only apply what I'd learn in the online courses I took, but also learn how to test ideas in interesting papers for myself.
In my first iteration, I wanted to learn Keras and coincidentally stumbled across a chest x-ray disease dataset on Kaggle. I then built an image classifier to determine whether a person's chest x-ray is normal or contains COVID19, viral pneumonia, or bacterial pneumonia.
In my second iteration, I wanted to explore classifying even more diseases in addition to displaying a confidence level for the predictions. I then built a new image classifier to do just that.
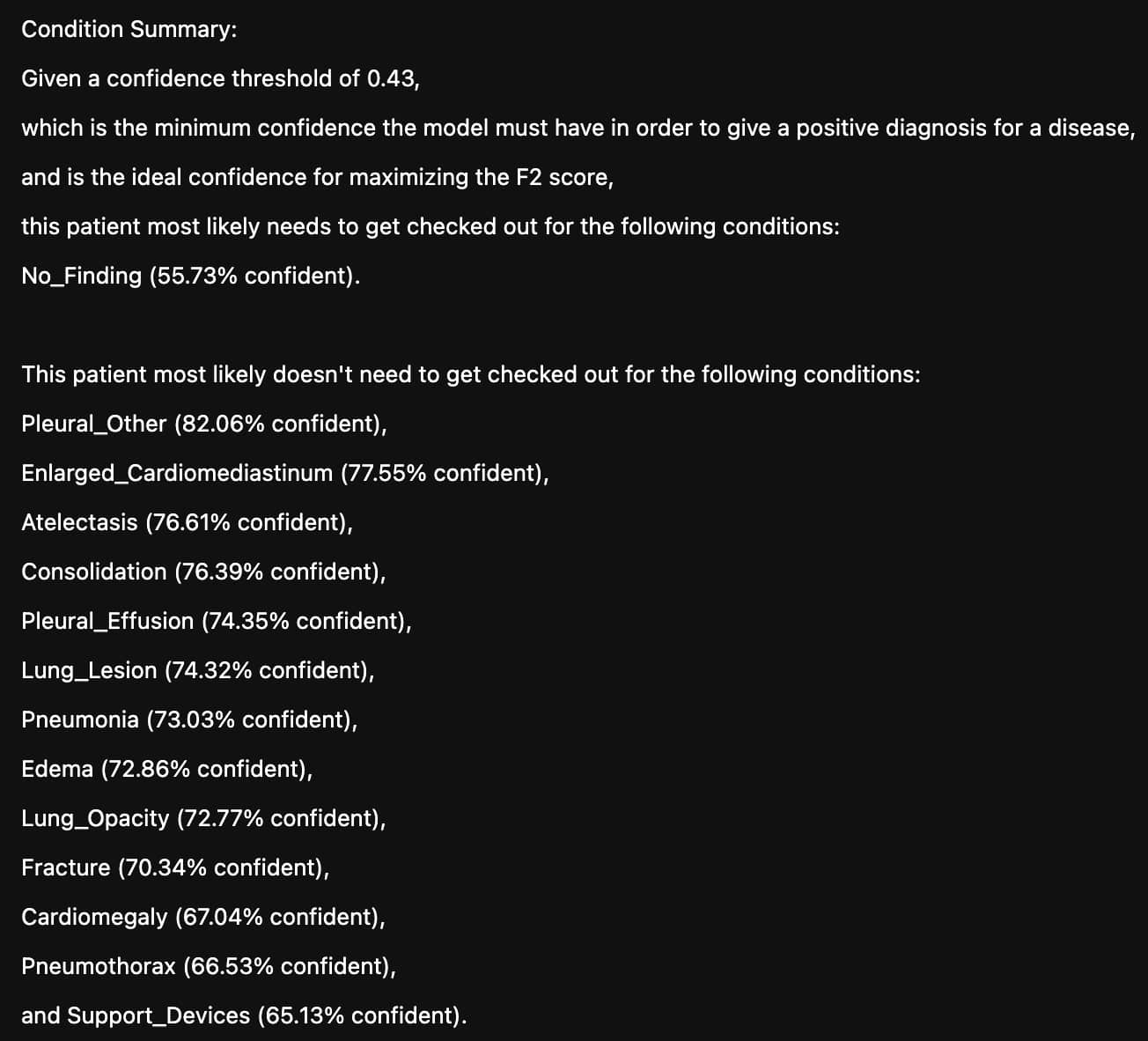
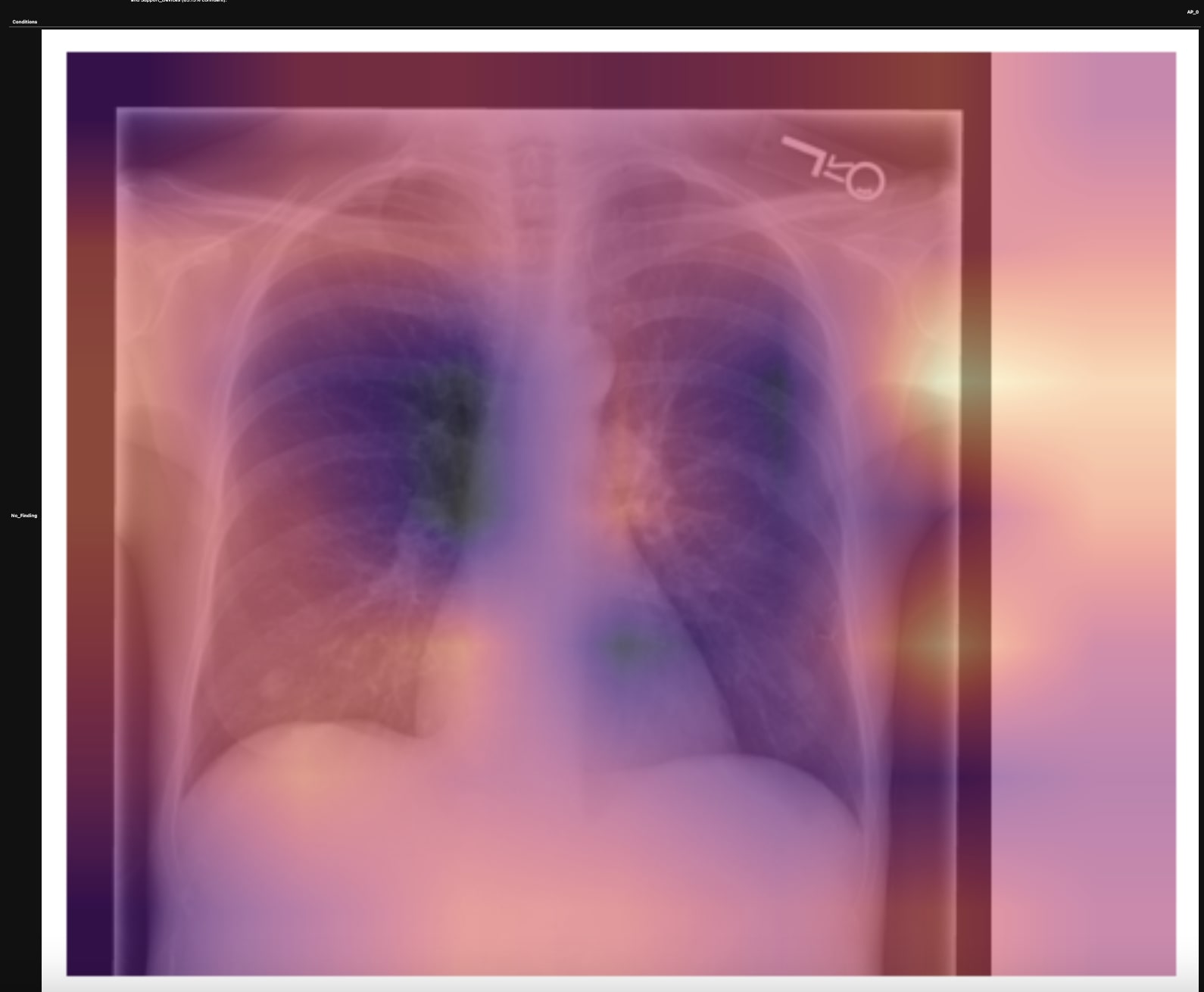
In my third iteration, I wanted to apply what I'd learned in the 2020 edition of the fast.ai course and took a different approach to this problem. I decided to train two models: a model that generates radiologist reports from the chest x-rays and a classification model that summarizes the generated report, the images, and other clinical data into a of diseases the patient most likely needs to be checked out for. I even got the chance to work with a biology teacher at my high school to help me understand the technical details of x-rays and the diseases they can detect, which culminated in a presentation for the entire school to see.
In my last iteration, I used around eight percent of the training set from the MIMIC-CXR dataset to improve the two above-mentioned models. In the end, the report generation model achieved a Bleu4 score of 0.0704 and the diagnosis model achieved a precision of .545 and a recall of .824. As a comparison, a contemporary SOTA model uses the entire training set to achieve a Bleu4 score of 0.103. For classification, the authors use an NLP labeler to achieve a precision of 0.333 and a recall of 0.273.
Links: First Iteration, Second Iteration, Third Iteration, Final Iteration, Report Generation Model , Multi-Modal Classification Model , SOTA Comparison , NLP Labeler
Awards
- GPU Mode Practice Round Winner
- Most Promising Entry @ ZenML MLOps Competition
- Top-25 Project of FSDL
- AP Scholar Award
- Black belt in Taekwondo, certified by World Taekwondo.
- Music Teachers National Association (MTNA) level 10 pianist.